Home
Featured
Publications
Contact
Light
Dark
Automatic
1
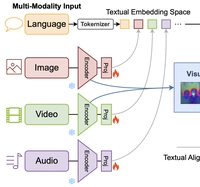
X-VILA: Cross-Modality Alignment for Large Language Model
Cross Video/Image/Language/Audio language foundation model.
Hanrong Ye
,
De-An Huang
,
Yao Lu
,
Zhiding Yu
,
Wei Ping
,
Andrew Tao
,
Jan Kautz
,
Song Han
,
Dan Xu
,
Pavlo Molchanov
,
Hongxu Yin
PDF
Cite
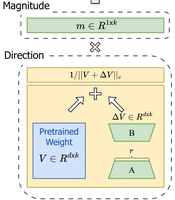
DoRA: Weight-Decomposed Low-Rank Adaptation
PEFT technique for efficient LLM/VLM adaptation. Significantly better than LoRA, supported in HF.
Shih-Yang Liu
,
Chien-Yi Wang
,
Hongxu Yin
,
Pavlo Molchanov
,
Yu-Chiang Frank Wang
,
Kwang-Ting Cheng
,
Min-Hung Chen
PDF
Cite
Code
Project
Video
ICML2024(Oral)
AM-RADIO: Reduce All Domains Into One
Best vision foundation model obtained via multiple model distillation like CLIP, DINOv2, SAM.
Mike Ranzinger
,
Greg Heinrich
,
Jan Kautz
,
Pavlo Molchanov
PDF
Cite
Code
CVPR2024
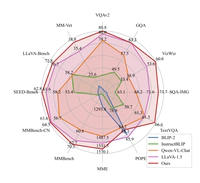
VILA: On Pre-training for Visual Language Models
Vision language foundation model. Multiple findings on how to train a better model.
Ji Lin
,
Hongxu Yin
,
Wei Ping
,
Yao Lu
,
Pavlo Molchanov
,
Andrew Tao
,
Huizi Mao
,
Jan Kautz
,
Mohammad Shoeybi
,
Song Han
PDF
Cite
CVPR2024
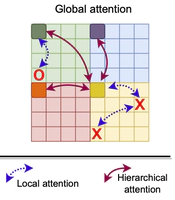
FasterViT: Fast Vision Transformers with Hierarchical Attention
Vision transformer architecture with new hierarchical attention optimized for throughput and high-resolution images.
A. Hatamizadeh
,
G. Heinrich
,
H. Yin
,
A. Tao
,
J. Alvarez
,
J. Kautz
,
P. Molchanov
PDF
Cite
Code
ICLR2024
Heterogeneous Continual Learning
Introducing a new problem of continual learning with architecture progression.
D. Madaan
,
H. Yin
,
W. Byeon
,
J. Kautz
,
P. Molchanov
PDF
Cite
Code
Video
CVPR2023 Highlight
Recurrence without Recurrence: Stable Video Landmark Detection with Deep Equilibrium Models
Application of Deep Equlibrium Models to landmark estimation. Train on single isolated images, apply on videos to reduce jitter. New video landmarks dataset.
P. Micaelli
,
A. Vahdat
,
H. Yin
,
J. Kautz
,
P. Molchanov
PDF
Cite
Code
Video
CVPR2023
Global context vision transformers
New vision transformer architecture optimized for number of parameters and FLOPs.
A. Hatamizadeh
,
H. Yin
,
J. Kautz
,
P. Molchanov
PDF
Cite
Code
ICML2023
LANA: Latency Aware Network Acceleration
Fast NAS-like techinue for trained model compression. Pretraines possible layer candidates via local distillation, does NAS via integer linear programming.
P. Molchanov
,
J. Hall
,
H. Yin
,
J. Kautz
,
N. Fusi
,
A. Vahdat
PDF
Cite
Video
ECCV2022
Structural pruning via latency-saliency knapsack
Fast NAS-like techinue for trained model compression. Pretraines possible layer candidates via local distillation, does NAS via integer linear programming.
M. Shen
,
H. Yin
,
P. Molchanov
,
L. Mao
,
J. Liu
,
J. Alvarez
PDF
Cite
Code
Video
NeurIPS2022
»
Cite
×