Home
Featured
Publications
Contact
Light
Dark
Automatic
Arxiv
AM-RADIO: Reduce All Domains Into One
Best vision foundation model obtained via multiple model distillation like CLIP, DINOv2, SAM.
Mike Ranzinger
,
Greg Heinrich
,
Jan Kautz
,
Pavlo Molchanov
PDF
Cite
Code
CVPR2024
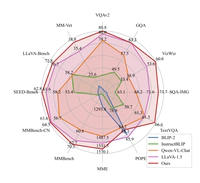
VILA: On Pre-training for Visual Language Models
Vision language foundation model. Multiple findings on how to train a better model.
Ji Lin
,
Hongxu Yin
,
Wei Ping
,
Yao Lu
,
Pavlo Molchanov
,
Andrew Tao
,
Huizi Mao
,
Jan Kautz
,
Mohammad Shoeybi
,
Song Han
PDF
Cite
CVPR2024
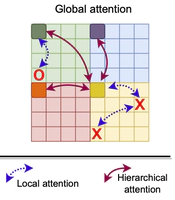
FasterViT: Fast Vision Transformers with Hierarchical Attention
Vision transformer architecture with new hierarchical attention optimezed for throughput and high resolution images.
A. Hatamizadeh
,
G. Heinrich
,
H. Yin
,
A. Tao
,
J. Alvarez
,
J. Kautz
,
P. Molchanov
PDF
Cite
Code
ICLR2024
Cite
×